本文共 2710 字,大约阅读时间需要 9 分钟。
目前,我们可以使用像、或这些高级的、专业的库和框架而不需要一直担心权重矩阵的大小,也不需要记住决定使用的激活函数的导数公式。通常我们只需要构建一个神经网络,即使是一个结构非常复杂的神经网络,也只需要导入一些库和几行代码。这节省了我们找出bug的时间,并简化了工作。然而,如果了解神经网络内部发生的事情,对架构选择、超参数调优或优化等任务有很大帮助。本文源代码可以在我的上找到。
介绍
为了更多地了解神经网络的原理,我决定写一篇文章,一部分是为了我自己,一部分为了帮助其他人理解这些有时难以理解的概念。对于那些对代数和微积分不太熟悉的人,我会尽量详细一些,但正如标题所示,这是一篇涉及很多数学的文章。
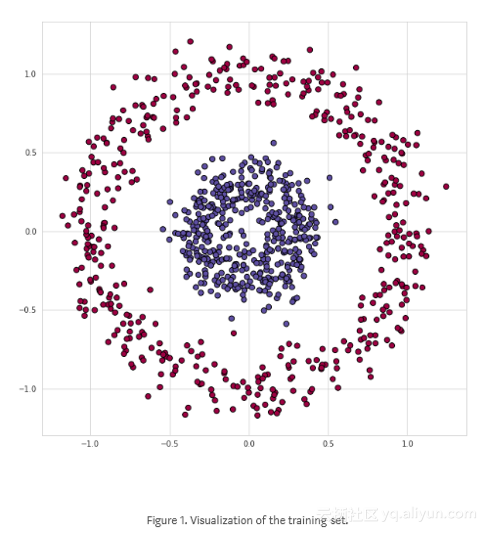
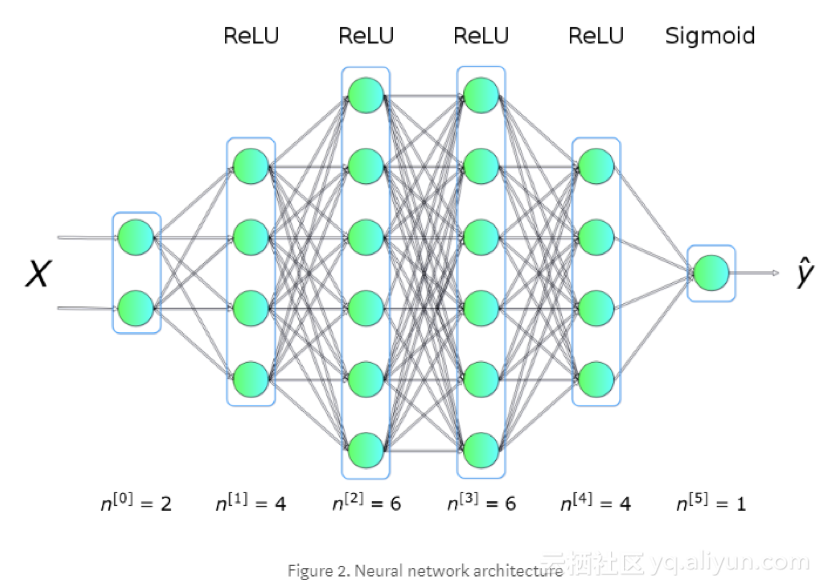
例如,我们将解决如图1所示的数据集二分类问题,两种类别的点形成圆圈,这种排列对于许多传统的ML算法来说是不方便的,但是一个简单的神经网络却可以很好地解决这个问题。为了解决这个问题,我们将使用一个神经网络,结构如图2所示。五个有不同数量单元的全连接层,对于隐藏层,我们将使用ReLU作为激活函数,对输出层使用Sigmoid。这是一个相当简单的架构,但复杂到足以成为我们深入探讨的例子。
KERAS解决方案
首先,我将介绍一个最流行的机器学习库之一KERAS
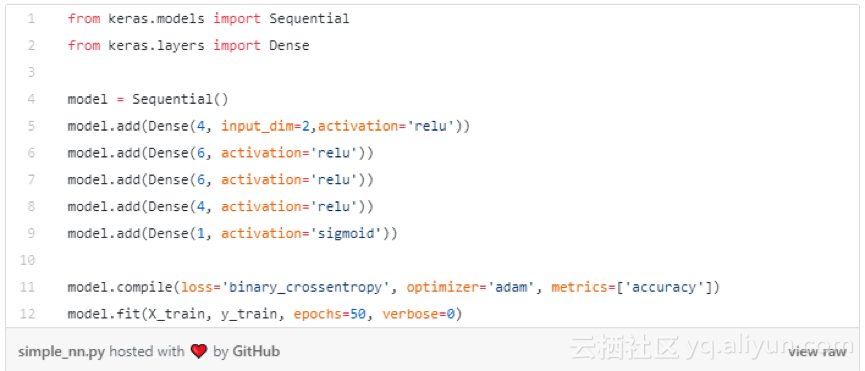
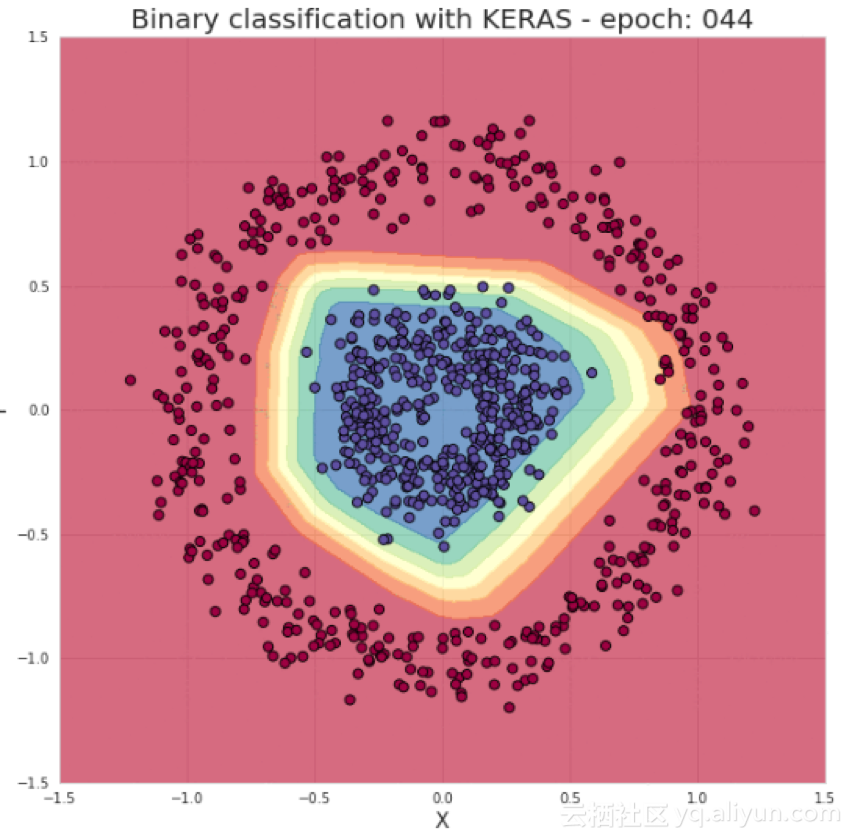
正如我在介绍中提到的,只要导入一些库和几行代码就足以构建和训练一个模型,该模型对训练集进行分类的准确率基本上可以达到100%。我们的任务归根结底是根据所选择的架构提供超参数(层数、层内神经元数、激活函数或epoch数)。现在让我们看看背后的原理。我在学习的过程中弄了一个非常酷的视觉效果,希望能让你提起兴趣。
什么是神经网络?
让我们从回答这个关键问题开始:什么是神经网络?这是一种生物启发的方法,可以构建能够学习和独立查找数据连接的计算机程序。网络是一组按层排列的软件“神经元”,以一种允许交流的方式连接在一起。
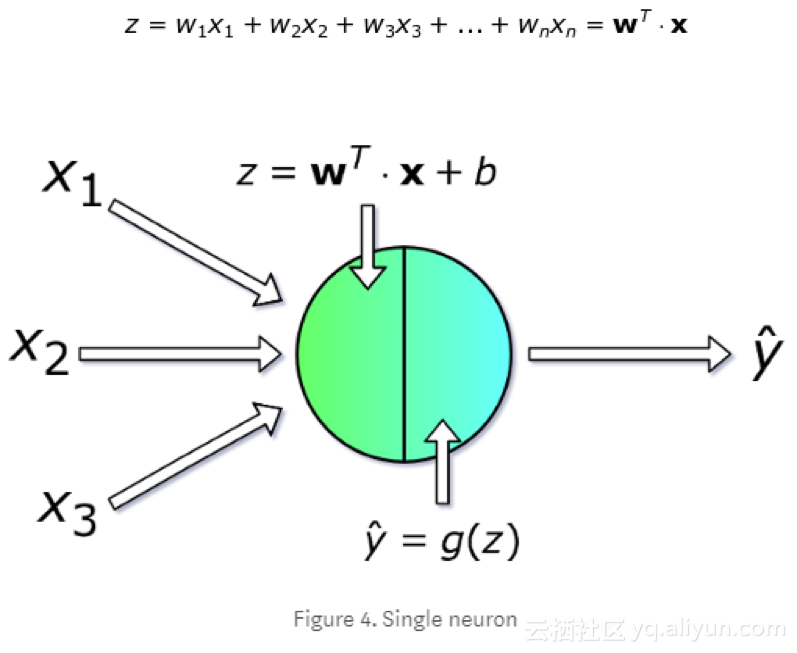
每个神经元接收一组变量x (从1到n编号)作为输入并计算预测的y值。向量x实际上包含了训练集中m个例子中的一个特征值。更重要的是,每个单元都有自己的一组参数,通常被称为w(权重列向量)和b(偏差),它们在学习过程中会发生变化。在每次迭代中,神经元根据向量x的当前权值w计算向量x的加权平均值并加上偏差。最后,通过一个非线性激活函数g来传递计算结果。
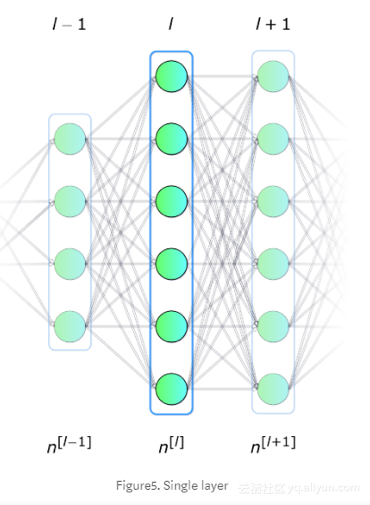
单层
先把范围缩小来考虑如何计算整个神经网络层,通过在单个单元内发生的原理来向量化整个网络层,将这些计算组合成矩阵方程。为了统一符号,为选定的层编写方程[l]。顺便说一下,下标i标记了这层神经元的顺序。
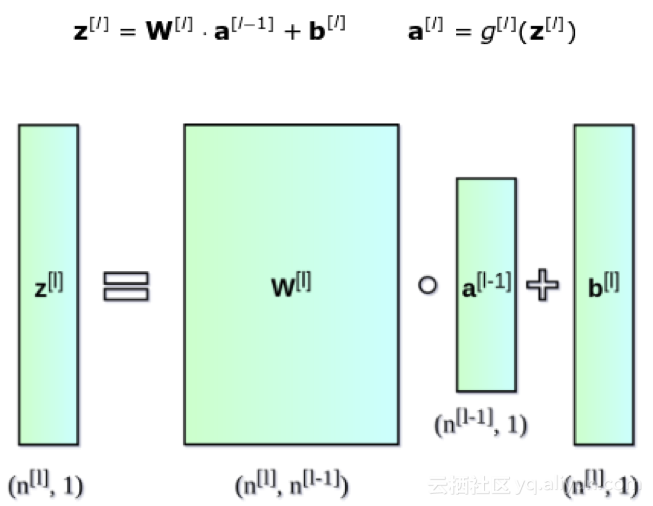
更重要的一点是:当我们写单个单元的等式时,我们使用x和y-hat来分别表示特征的列向量和预测值。在切换到层的通用符号时,使用向量a——表示对应层的激活。因此,x向量表示第0层的激活,也就是输入层。层中的每个神经元按照如下公式进行计算:
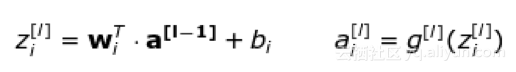
为了清楚起见,写出第2层对应的方程:
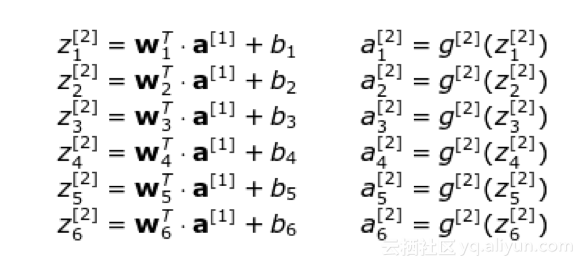
就像看见的那样,对于每个层的操作原理都差不多。在这里使用for循环并不十分有效,因此为了加快计算速度,我们将使用向量化来进行加速。首先,把转置后的权重w的水平向量叠加起来来构建一个矩阵w。同样,我们可以把每个神经元的偏移值叠加起来构建一个垂直向量b。现在没有什么可以阻止我们建立一个矩阵方程来计算所有神经元层,以下是会用到的矩阵和向量的维度。
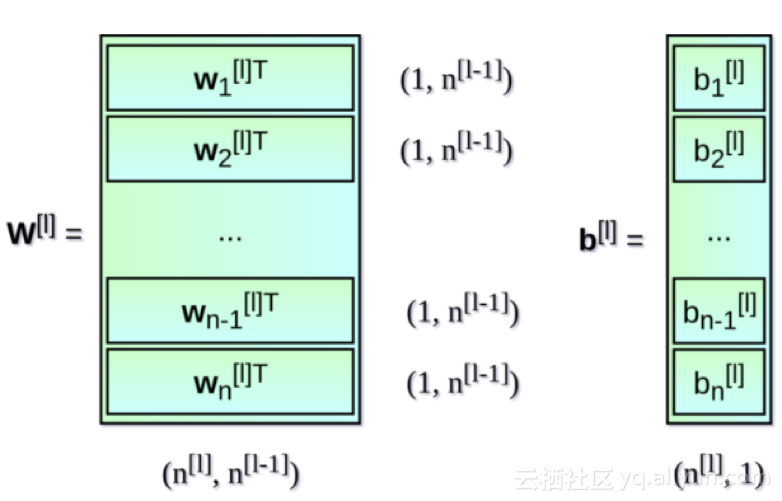
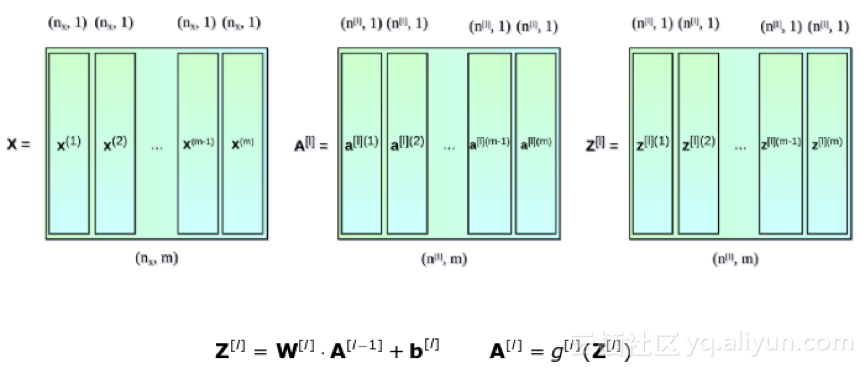
对多样本向量化
到目前为止我们列出的方程只涉及到一个样本。在学习神经网络的过程中,你通常要处理大量的数据,多达数百万个样本。因此,下一步将对多个样本进行向量化。假设我们的数据集有m个样本,每个样本都有nx特征。首先,我们将把每一层的垂直向量x、a,和z放在一起来分别创建x, a和z矩阵。然后,重写之前的简化方程来应用新的矩阵。
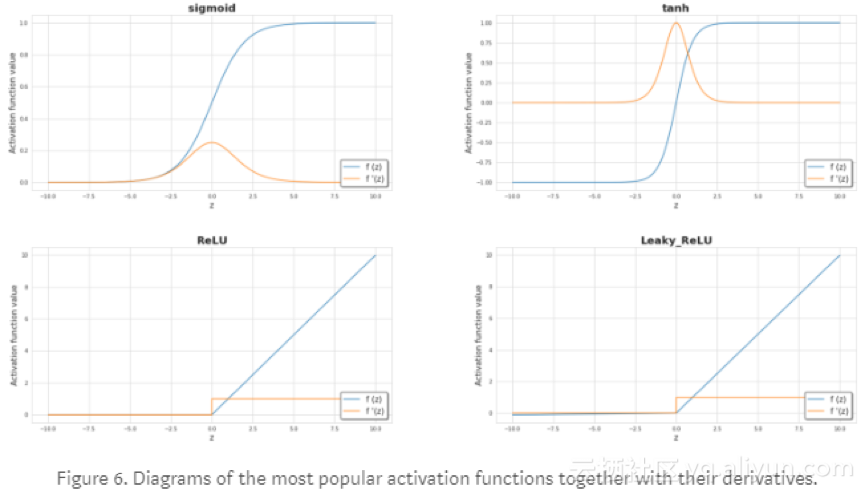
什么是激活函数?我们为什么需要它?
激活函数是神经网络的关键要素之一。没有它们,我们的神经网络就会变成线性函数的组合,那么它本身还是一个线性函数。我们模型的可扩展性有限,不会比逻辑回归要好。非线性元素在学习过程中有很好的弹性和并且可以构建比较复杂的函数。激活函数对学习速度也有显著影响,所以激活函数也是选择的一个重要标准。图6列出了一些常用的激活函数。目前,最流行可能是ReLU。但我们有时仍然使用sigmoid,当我们处理二分类问题时,希望模型返回的值在0到1之间,会在输出层使用sigmoid。
损失函数
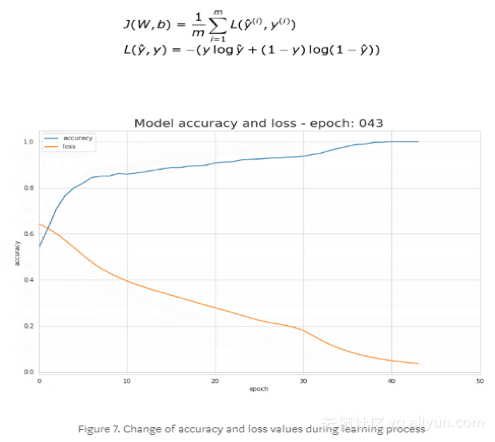
关于学习过程的基本信息来源是损失函数。一般来说,损失函数是用来衡量我们离“理想”的解决方案有多远。在我们的例子中使用了二元交叉熵,但是根据问题的不同可以应用不同的函数。我们使用的函数如下式所示,学习过程中其值的变化如图7所示。它显示了每一次迭代的损失函数值降低和准确率的提高。
神经网络如何学习?
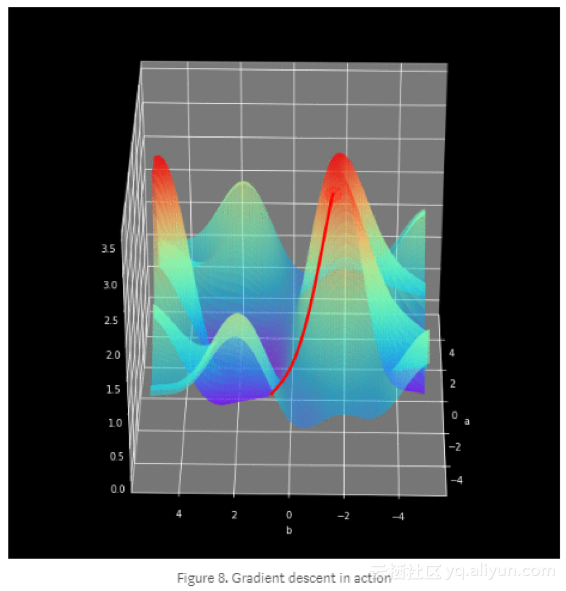
神经网络学习过程即改变W和b参数的值,使损失函数最小化。为了实现这一目标,我们将借助于微积分,使用梯度下降法来求出函数的最小值。在每次迭代中,我们将计算损失函数对于神经网络每个参数的偏导数的值。对于那些不太熟悉这种计算方法的人,我只想提一下导数有一种神奇的能力来描述函数的斜率。由于这一点,我们知道如何调整参数来使图形上下移动。为了能够直观地了解梯度下降法的工作原理,我准备了一个小的可视化。你可以看到,随着epoch一直走,我们是如何实现最小化的。在神经网络中,它工作的原理也差不多,在每次迭代中用计算的梯度来显示我们应该移动的方向,主要的区别是在实际的神经网络中,我们有更多的参数要操作,重点是:如何计算这些复杂的导数?
反向传播
反向传播是一个允许我们计算非常复杂的梯度的算法,根据以下公式调整神经网络的参数。
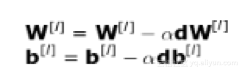
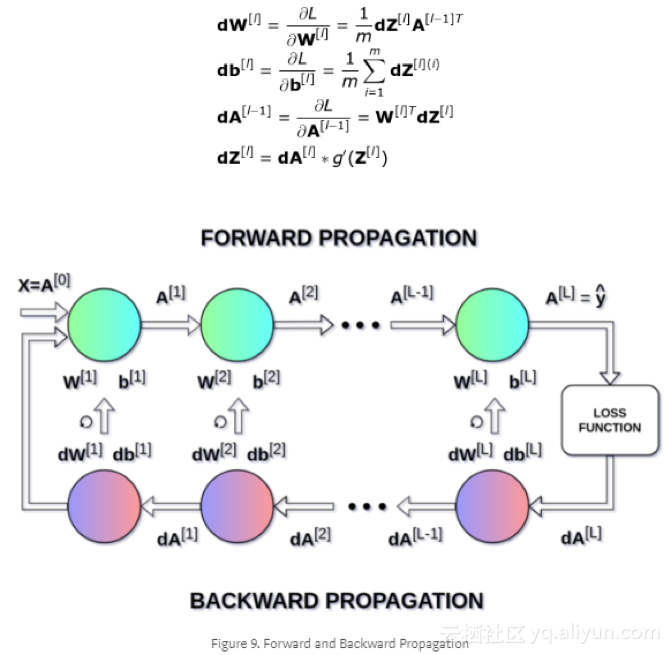
在上面的等式中,α表示学习率——是调整变量的一个超参数。选择一个学习率是至关重要的——如果我们设置的太低,神经网络学习的非常缓慢,我们设置的太高,我们将无法找到最小值。利用链式法则计算dW和db,即损失函数对W和b的偏导数,dW和db的大小,跟W和b是一样的。图9显示了神经网络中的操作序列。我们清楚地看到前向传播和反向传播如何协同工作来优化损失函数的。
结论
希望我已经解释了在神经网络中发生的数学,但至少了解了这部分内容对以后的神经网络的工作是很有帮助的。我认为文章提到的内容是最重要的,但它们只是冰山一角。我强烈建议你自己尝试搭建这样一个小型的神经网络,不使用高级框架,只使用Numpy。
如果你看到这里,恭喜你!这篇文章并不是那么容易阅读。
本文由组织翻译。
文章原标题《deep-dive-into-deep-networks-math》
作者: 译者:乌拉乌拉,审校:。
文章为简译,更为详细的内容,请查看。
转载地址:http://gmmpx.baihongyu.com/